I work with a lot of users using our Octopus Deploy server on a daily basis. It seems that not all, but many of our users don’t fully grasp the philosophy behind automated deployments so I thought a rant was in order. If you’re using Octopus Deploy or even thinking about implementing it, Octopus is indeed a great first step into automation – but that’s it. It’s the first step – not the final step. Simply using Octopus Deploy doesn’t mean you’re automating your deployments. How so?
I find that many users, misunderstand deployment automation because they simply translate the manual steps of what was previously done (sometimes verbatim) into Octopus Deploy. Many users are confused as their previous manual deployments had always worked before, but within Octopus their deployments can fail seemingly at random. Some users try to get very creative, even beyond their understanding of what they intended to do or the purpose of the steps they’re executing. Ultimately what users fail to realize is that the concepts of manual deployments and automated deployment are completely incompatible with one another. People like to think that there’s some overlap between the two, but frankly there isn’t. In Octopus Deploy, you need construct your deployment process from scratch – not just recreate your previous manual process. In order to be successful in automating your deployments, you need to design your deployment process from a minimalist zen-like implementation with a “fire-and-forget” approach.
Too often I see some of our users deploying by manually skipping steps for certain environments. While some may say they like the level of control (or whatever reason they can think of), this is not considered an automated deployment. If anything creating large deployment processes with specific steps for specific environments is a recipe for disaster. For example, one team that tried deploying to staging had run into a repeated failure as one of their files was locked in their installation directory. Out of the 43 steps in their deployment process, they forgot to stop IIS for their staging environment. This example may be easy to fix but the core lesson behind this is: don’t rely on someone to reliably configure your deployments. Human error is far more possible than people admit. It may seem like it’s easy to enable/disable steps – but that isn’t automation. The general purpose of automation is to remove human interaction – not to extend it.
Here’s an example of common (simplified) example of a deployment process I see from time to time. Note on the left side (blue) is a poor, lengthy, intricate series of steps that are specific towards an environment or a particular server. On the right side (green), steps are consolidated into simple, encompassing, and adaptive to any environment. The blue side can/may represent what was done manually before Octopus Deploy. The manual steps do not translate well at all in terms of automation, reliability and speed.
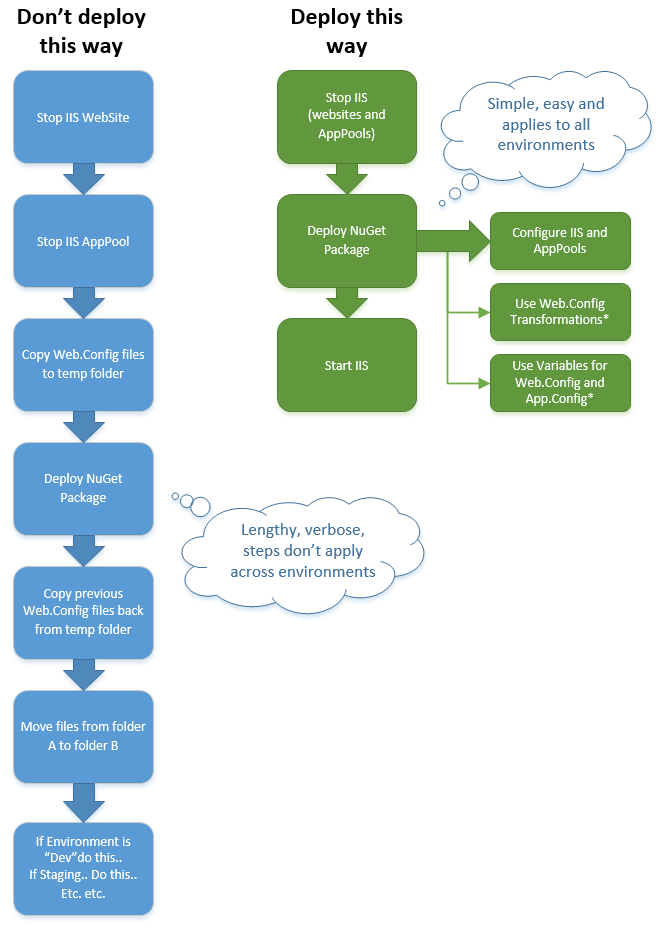
I’ve seen deployment processes that have exceeded 40, 50 and 60 steps; these steps require users to enable/disable steps for a given environment. This old tried-and-true manual way of deploying project is really a curse in disguise. In spite of those users not realizing the logical gaps between manual and automated processes – there’s nothing about a manual process that translates to automation. From manual intervention steps, to backing up projects, backing up web.configs and moving them back into place after a NuGet package contents have been installed, to manually moving files around, users often don’t realize that automation requires a completely different perspective from how they used to implement their deployments.
I want to point out that not all of our users misuse Octopus; many use it very well. Users and/or teams that do well typically ask a lot of questions, learn new techniques and try out different approaches repeatedly and consistently deploy day by day across their environments. They put the time and effort in and it shows. I can see the consistency of consecutive successful deployments that have been promoted between their environments. I also see the deployment times gradually decreasing with respect to newer releases. The biggest sign of a team that uses Octopus Deploy well: their production deployments go smoothly.
The reason I’m stating this philosophical stance of how automated deployments need to be treated in terms of a zen-like minimalist perspective is due to the fact that many of our users and teams still lean on bad manual habits of before and treat automation no differently. Using Octopus Deploy to automate your deployments means you have to orchestrate steps, variables and NuGet packages in such a way that guarantees 100% certainty that the deployments will work as expected – with no manual configuration or intervention. This is the “fire-and-forget” approach of deployment automation. Any possible deviations in configurations or unstructured application changes are just vectors for possible failure. But as I’ve learned over time – most users don’t see it that way.
I’ve come to accept the fact that a minority of users may view Octopus Deploy as an extension or rather a “dip” of their toes into the systems administration pool without getting their feet wet. All the settings they wanted to tinker with and change on the fly (within their desired time frame) they now have the keys to the kingdom to do so. Of course, with that power comes the requisite knowledge of how to weld everything properly but the comprehension that’s required from said users I’ve found to be severely lacking.
Octopus Deploy makes deployments very easy to orchestrate – perhaps too easy. Having the Octopus Step Template Library also allows users with minimal to no PowerShell knowledge at all to do more systems administration type tasks with zero understanding of the actual inner workings. Is this dangerous or bad? Insert typical tech answer here: it depends. Should developers know more about IIS, Windows Services, SQL Server, etc.? Absolutely. But that responsibility is on those whom have the ability to deploy at will and there’s the catch. The friction I’m seeing with users and teams that struggle with automating their deployments is a direct result of the fact that they don’t fully understand the technology that they’ve been shielded from for so long. That’s why they keep sticking to the same routine as before – they don’t really know what to do from scratch because they don’t know how these systems actually work. So what can you do to move towards faster, reliable deployment automation?
1. Assess – Take an accurate inventory/stock of your knowledge. Acknowledge what you know but more importantly what you don’t know. If you don’t know IIS, now’s the time to learn. Not familiar with sc.exe for installing your Windows Service? Saddle up. You know PowerShell but don’t know NuGet? Now’s the time to tinker with NuGet.exe and your NuSpec file. I don’t know every little bit of technology I work with, but I can immediately recognize when I’m out of my depth. I have no shame nor arrogance about it, but I make sure to be true to myself in acknowledging that which I don’t know. From there I have to start asking questions – good questions too. From there I can proceed further and start figuring out a way to understanding what I don’t know.
2. Learn how to learn – If you don’t know something, start by researching. Books, websites, blogs, whatever. There’s so much information available it’s merely a matter of taking the time to do so and dig around. If you’re not very good at researching, the only way to get better is to practice – so why not start now? Additionally, one of the best things about practicing is that it should lead you to ask more questions relevant to the problems you may be having. The more questions you have, the better to answer them. When you get good at asking questions, you’ll be able to focus on the more important questions as they arise – and eventually you may solve problems faster than before simply by learning to ask the right questions.
3. Practice – The cure to these ailments is practice. After that? Adjustments and.. you guessed it: more practice. And then more learning followed by practice. I view every deployment in non-production environments as an opportunity to prepare for a production deployment, but it’s also an opportunity for you to learn more about the systems you’re working with. Reading manuals may be in your near future – and it’s a good thing. There’s no magic bullet for this – if you’re automating your deployments you’re going to have to understand more about your systems than you did as a developer as well as your packaging and your configurations – intimately.
4. Communicate – If you still can’t figure out something or need help, ask! Not asking isn’t going to help anyone – especially you. But be aware – asking for help means you need to put forth the time and effort of trying to solve your problems as well. Simply stopping on every minor road bump isn’t going to get you to your goal any quicker and ultimately, you won’t really learn anything new if you’re constantly depending on others.
Every now and then I’m reminded of a quote Carl Sagan once said about humans and technology.
We have also arranged things so that almost no one understands science and technology. This is a prescription for disaster. We might get away with it for a while, but sooner or later this combustible mixture of ignorance and power is going to blow up in our faces
The quote may be a little hyperbolic, but the sentiment is fitting. My goal of this rant isn’t to intimidate or pressure (okay maybe there is a little pressure here), but to educate and promote a proper deployment automation philosophy. Whether you’re using Octopus Deploy or not, deployment automation is always worth doing. And while I prefer Octopus Deploy, the principal of Zen-like philosophy with the “fire-and-forget” approach really is a winning combination that could be applied beyond deployment automation. Like anything else in life, starting is the hardest part but like everything else, it can be mastered.
Great post.
Though one thing. Our steps are
– Check dependencies
– Deploy package into new folder
– Do transforms
– Create *new* IIS website
– Swap bindings
– Delete old website
– Notify team
There’s no outage as there would be on a stop/deploy/start (well maybe a millisecond or two, tops). There’s a post lined up about this process on the Domain tech blog, due to be published soon. It’s been working great for the last several months, and last time I checked we’d put something over 500 individual incremental deploys through it, with individual deployment tasks numbering well into the thousands.
Good point. The step really isn’t configuring IIS as it’s creating it if it doesn’t exist; if it does exist, it’s using the settings/values given but yes, your point is more succinct: create a new IIS site.Oh I see now. Clever. Two IIS sites and then swap bindings and delete the old site. That’s pretty interesting. I might have to give that a try.
Yeah, it’s pretty cool. I used to be an IIS MVP and I stood there and went “whoah” when it was explained to me.
Then again, I was an MVP before IIS 7 and powershell arrived so there you go.
I shared the step template with the guys over at OctopusDeploy, so maybe this’ll be native in v.next 😉
Pretty slick the more that I think about it. Granted for our environments, we have load balancers so we typically deal with Keep-Alives, but for the general public the swapping of the sites makes sense and it’s just another web deployment method available for Octopus. How do you deal with naming the sites within IIS? Do you use the same AppPool or create a new one? Do you generate the name to be used for the swap or do you have a standard format you stick to?
New app pool, new site. There’s a version that does a basic warmup of the newly created site before switching, but we have the luxury of being on a microservice platform, so that’s minimal work. It also sometimes fails in AWS so we generally leave it out.
new site name is based on the service name with a prefix, so I guess you could say partially generated. using the Octopus deploymentID or taskID would be a good way of handling that in a future version
Once it goes live, it’s renamed ready for the next deployment to roll through, and the old sites are cleaned up.
Now that 2.6 can do steps in parallel, do you think you can leverage them in doing the swap or maybe doing the warmup first then the swap?
Pingback: Variables are your friend | Ian Paullin